На данный момент, мало кто задумывается о том, как сжатие файлов. По сравнению с предыдущим использование персонального компьютера стало намного проще. И почти каждый человек, работающий с файловой системой, - это архивы. Но мало кто задумывается о том, как они работают и на каком основании сжатия файлов. Первый вариант этого процесса были коды Хаффмана, и они используются по сей день в различных популярных архиваторов. Многие пользователи даже не догадываются, насколько легко это сжатие файла и как это работает. В этой статье мы рассмотрим, каким образом сжатия, какие нюансы помогают ускорить и упростить процесс кодирования, а также взглянуть на то, что принцип построения дерева кодирования.
История алгоритма
 Вам будет интересно:Когда в "Ютуб" "Ютьюб" (YouTube). Датой основания создатели
Вам будет интересно:Когда в "Ютуб" "Ютьюб" (YouTube). Датой основания создатели
Первый алгоритм для эффективного кодирования цифровой информации становится код, предложенный Хаффманом в середине ХХ века, в 1952 году. В настоящее время он является основным базовым элементом большинства программ, созданных для сжатия информации. На данный момент одним из самых популярных источников, которые используют этот код несколько ZIP-архивов, шнур ARJ, RAR и многие другие. 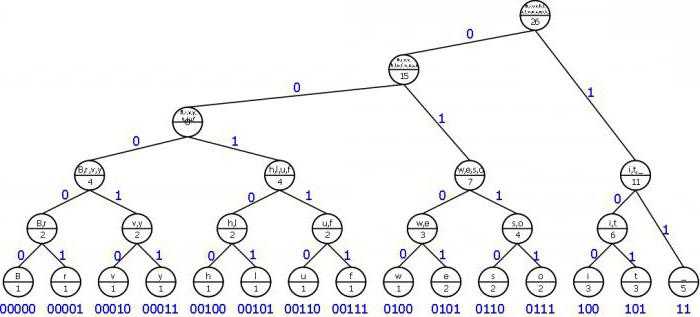 Кроме того, алгоритм Хаффмана используется для сжатия JPEG-изображений и других графических объектов. Ну, все современные факсимильные аппараты могут использовать кодирования, изобретенный в 1952 году. Несмотря на то, что с момента генерации кода прошло так много времени, по сей день применяется в новых снарядов и оборудования как старых, так и современных типов.
Кроме того, алгоритм Хаффмана используется для сжатия JPEG-изображений и других графических объектов. Ну, все современные факсимильные аппараты могут использовать кодирования, изобретенный в 1952 году. Несмотря на то, что с момента генерации кода прошло так много времени, по сей день применяется в новых снарядов и оборудования как старых, так и современных типов.
Принцип эффективного кодирования
 Вам будет интересно:Аймакс 3Д в Москве. Москве кинотеатры IMAX 3D с:
Вам будет интересно:Аймакс 3Д в Москве. Москве кинотеатры IMAX 3D с:
Алгоритм Хаффмана является частью схемы, которая может заменить наиболее вероятным, и наиболее распространенные символы, двоичные коды системы. И те, что возникают реже, заменяются на более длинные коды. Переход на длинные коды Хаффмана возникает только после того, как система использует все минимальные значения. Данная методика позволяет минимизировать длину кода для каждого символа исходного сообщения в целом. 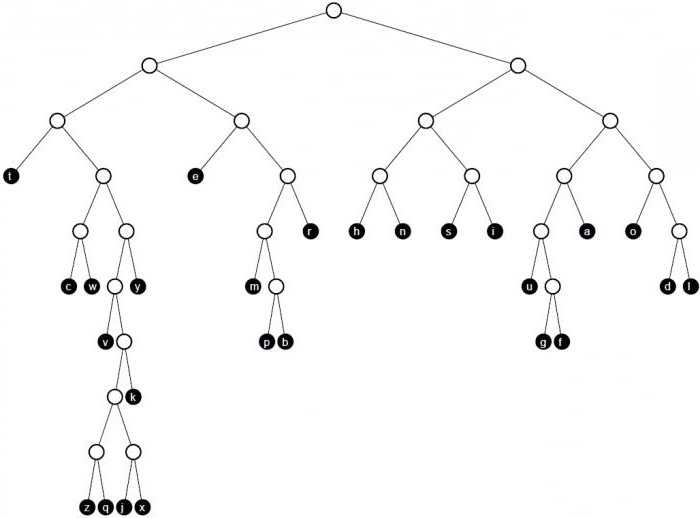 Важным моментом является то, что в начале кодирования вероятность появления буквы должны быть уже известны. Они будут конечными сообщение. На основе этих данных построить дерево кода Хаффмана кодирования, на основе которого и будет осуществляться процесс кодировки писем в архиве.
Важным моментом является то, что в начале кодирования вероятность появления буквы должны быть уже известны. Они будут конечными сообщение. На основе этих данных построить дерево кода Хаффмана кодирования, на основе которого и будет осуществляться процесс кодировки писем в архиве.
Пример кода Хаффмана
Для иллюстрации алгоритма рассмотрим графический вариант построения дерева кода. Чтобы использовать этот метод, чтобы быть эффективным, необходимо уточнить определение определенных ценностей, которые необходимы для понятия этого метода. Набор дуг и узлов, которые передаются от узла к узлу, называется графом. Само дерево представляет собой граф с множеством специфических свойств:
- в каждом узле может быть более одной дуги;
- один из узлов должен быть корень дерева, то есть он не должен входить в дугу на всех;
- если от корня, чтобы начать двигаться по дугам, этот процесс позволит вам получить полностью в любом из узлов.
 Есть еще и такая вещь, которая является частью коды Хаффмана, как кусок дерева. Это узел, от которого должны быть ни в дугу. Если две вершины соединены дугой, один из них является родителем другого ребенка, в зависимости от того, на какой узел дуги выходит, и что входит. Если два узла имеют общий родительский узел, их называют братские узлы. Если, помимо листьев, в узлах из нескольких дуг, то это дерево называется бинарным. Просто так это дерево Хаффмана. Характеристика узлов этой конструкции является то, что вес каждого из родителей равен сумме весов всех узлов детей.
Есть еще и такая вещь, которая является частью коды Хаффмана, как кусок дерева. Это узел, от которого должны быть ни в дугу. Если две вершины соединены дугой, один из них является родителем другого ребенка, в зависимости от того, на какой узел дуги выходит, и что входит. Если два узла имеют общий родительский узел, их называют братские узлы. Если, помимо листьев, в узлах из нескольких дуг, то это дерево называется бинарным. Просто так это дерево Хаффмана. Характеристика узлов этой конструкции является то, что вес каждого из родителей равен сумме весов всех узлов детей.
Алгоритм построения дерева Хаффмана
Построение кода Хаффмана состоит из букв входного алфавита. Сформирован список тех узлов, которые являются свободными в будущем дерево кода. Вес каждого узла в этом списке должны быть такими же, как вероятность появления буквы сообщения, соответствующего этому узлу. Кроме того, среди немногих свободных узлов будущего дерева выберите тот, который весит меньше. В этом случае, если минимальные значения наблюдаются на нескольких сайтах, можно свободно выбрать любой из пар. 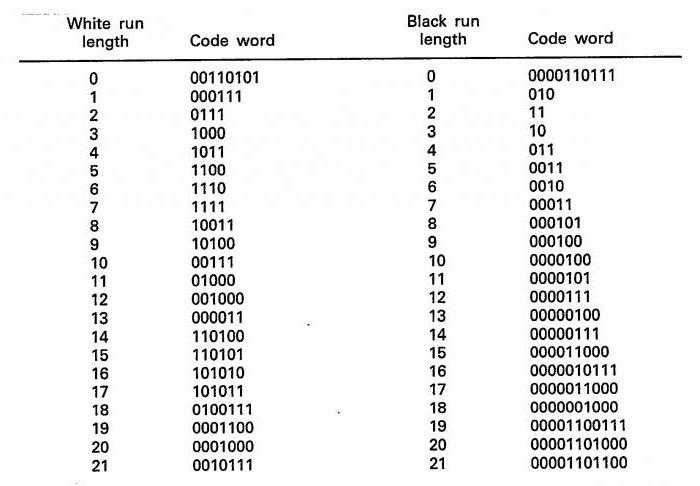 То есть создание родительского узла, которые должны весить столько, сколько весит объем этой парой узлов. После этого родители отправляют в список свободных узлов, а детей забирают. Дуги получат соответствующие цифры единиц и нулей. Этот процесс повторяется столько, сколько нужно, чтобы оставить только один узел. Затем двоичные числа записываются в направлении сверху вниз.
То есть создание родительского узла, которые должны весить столько, сколько весит объем этой парой узлов. После этого родители отправляют в список свободных узлов, а детей забирают. Дуги получат соответствующие цифры единиц и нулей. Этот процесс повторяется столько, сколько нужно, чтобы оставить только один узел. Затем двоичные числа записываются в направлении сверху вниз.
Повышение эффективности сжатия
Для повышения эффективности сжатия, необходимо при построении дерева код, чтобы использовать все данные, касающиеся вероятности появления букв в определенном файле, прикрепленном к дереву и допустить, что они были разбросаны на большое количество текстовых документов. Если предварительно пройти через этот файл, вы можете сразу же подсчитать статистику того, как часто письма от объекта компрессии.
Ускорение процесса сжатия
Для ускорения алгоритма, определение букв не нужно проводить с точки зрения вероятности появления тех или иных букв, и периодичность ее возникновения. Благодаря этому, алгоритм становится проще и гораздо быстрее. Также это позволяет избежать операций с плавающей запятой и деление. 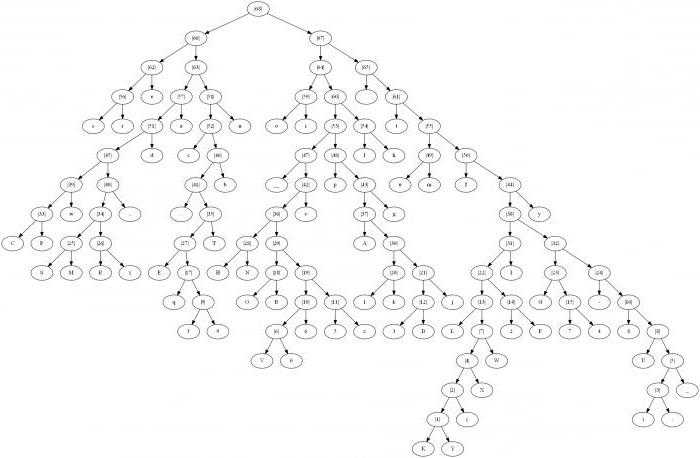 Кроме того, работая в этом режиме, динамический код Хаффмена, а скорее алгоритм, который не подлежит никаким изменениям. Это в основном объясняется тем, что вероятности имеют прямую пропорциональную частоте. Вы должны обратить особое внимание на то, что окончательный вес файла или так называемого корневого узла равна сумме количества букв в объект обработки.
Кроме того, работая в этом режиме, динамический код Хаффмена, а скорее алгоритм, который не подлежит никаким изменениям. Это в основном объясняется тем, что вероятности имеют прямую пропорциональную частоте. Вы должны обратить особое внимание на то, что окончательный вес файла или так называемого корневого узла равна сумме количества букв в объект обработки.
Заключение
Коды Хаффмана - простые и устоявшиеся алгоритм, который до сих пор используется на многих известных программ и компаний. Его простота и ясность позволяют добиться эффективных результатов в сжатии файлов любого размера и значительно уменьшить занимаемое пространство на вашем диске. Другими словами, алгоритм Хаффмана – давно изучены и отработаны схемы, актуальность которых не снижается и по сей день. 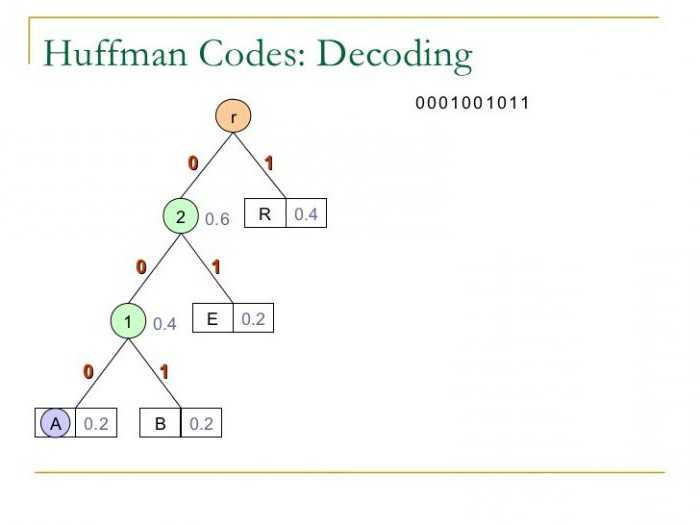 И с возможностью уменьшить размер файлов, их передачи через сеть или другими способами становится более простым, быстрым и удобным. Работая с алгоритмом, может сжимать абсолютно любую информацию без вреда для ее структуры и качества, но с максимальным эффектом уменьшения веса файла. Другими словами, кодирование кодом Хаффмана был и остается самым популярным и актуальным методом сжатия размера файла.
И с возможностью уменьшить размер файлов, их передачи через сеть или другими способами становится более простым, быстрым и удобным. Работая с алгоритмом, может сжимать абсолютно любую информацию без вреда для ее структуры и качества, но с максимальным эффектом уменьшения веса файла. Другими словами, кодирование кодом Хаффмана был и остается самым популярным и актуальным методом сжатия размера файла.