- Информация в информатике
- Кодирования информации в электронные вычислительные машины
- Системы бухгалтерского учета в компьютерной сфере
- Алфавитный подход к измерению информации: сущность единицы
- Появление Ravnomernaya символов в текстовом файле
- Различные вероятности появления символов в тексте
- Измерение информации: тонкости семантического аспекта
- Событий, встретиться с равной вероятностью
- Пример расчета событий ravnovesnogo
- Измерительной информации с учетом различных вероятностей появления события
- Различия между алфавитным и содержательным подходами к информационной размерности
- Выводы
Развитие компьютерных технологий в новом информационном веке возникает много дополнительных вопросов, открывает новые возможности и знания. Но в то же время есть много дилемм, которые нужно решать. Так, например, изучая компьютерные технологии, важно понять, как он обрабатывает, хранит и передает файлы, что такое кодирование данных и в каком формате измерительной информации. Но главным предметом обсуждения является вопрос о том, каковы основные подходы к измерению информации. Примеры и объяснения каждого аспекта будут подробно описаны в данной статье.
Информация в информатике
 Вам будет интересно:Как изменить картинку на рабочем столе: руководство пользователя
Вам будет интересно:Как изменить картинку на рабочем столе: руководство пользователя
Чтобы приблизиться к пониманию информационного подхода хранения данных, сначала нужно знать в компьютерной сфере-это информация, и это видно. Потому что если вы берете информатики как науки, ее основным объектом изучения является информация. Само слово имеет латинское происхождение и в переводе на наш язык означает "введение", "объяснение", "Примечание". Каждая наука использует различные определения данного понятия. В компьютерной сфере, всю информацию о различных явлениях и объектах, которые нас окружают, которые уменьшают меру неопределенности и степень нашего незнания о них. Но для сохранения всех файлов, данных, символических знаков в электронные вычислительные машины, необходимо знать алгоритм перевода в двоичную форму и существующие единицы измерения количества информации. Алфавитный подход к измерению информации показывает, как компьютерная машина преобразует символы в двоичный код из единиц и нулей.
Кодирования информации в электронные вычислительные машины
 Вам будет интересно:Как передать большой файл через Интернет? Быстрый способ передать файл
Вам будет интересно:Как передать большой файл через Интернет? Быстрый способ передать файл
Компьютерная техника способна распознавать, обрабатывать, хранить и передавать информационные данные только в двоичном коде. Но если это аудио, текст, видео, графические изображения, как и машины, способные на различные типы данных для преобразования в двоичную? И как они такой хранить в памяти? На эти вопросы ответы можно найти, если вы знаете алфавитный подход к определению количества информации, содержательный аспект и технической сущности кодирования.
 Вам будет интересно:IT-технологии - что это? Для чего нужен он?
Вам будет интересно:IT-технологии - что это? Для чего нужен он?
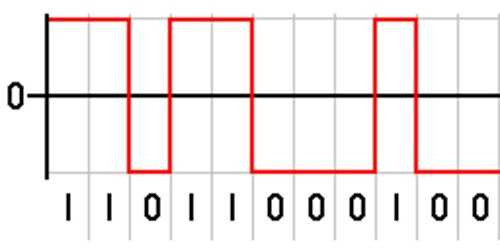
Информация, кодирование для кодирования символов в двоичный код, состоящий из цифр "0" и "1". Это технически легко организовать. Сигнал, если прибор ноль показывает обратное. Некоторые задаются вопросом о том, почему компьютер не может, как человеческий мозг для хранения комплексных чисел, потому что они меньше по размеру. Но электронной вычислительной техники легче справиться с огромными двоичный код, чем хранить в своей памяти комплексные числа.
Системы бухгалтерского учета в компьютерной сфере
Мы привыкли считать от 1 до 10, складывать, вычитать, умножать и делать различные операции над числами. Компьютер может оперировать только двумя цифрами. Но делает это в доли миллисекунд. Как компьютер машина кодирования и декодирования символов? Это достаточно простой алгоритм, который можно рассматривать в качестве примера. Алфавитный подход к измерению информации, единицы измерения данных, мы будем обсуждать чуть позже, после того, как станет ясна суть кодирования и декодирования данных.
Существует множество компьютерных программ, которые достаточно перевести систему расчета или текстовую строку в двоичные и обратно.
Мы будем проводить расчеты вручную. Информация кодирования в привычном делении на 2. Итак, допустим, у нас есть десятичное число 217. Нам нужно преобразовать его в двоичный код. Для этого разделим его на число 2 в данный момент, в то время как остальные не будут работать, ноль или один.
- 217/2=108 с остатком 1. Отдельно оплачивается остатки, и они будут создавать наш окончательный ответ.
- 108/2=54. Вот остаток-это число 0, так как 108 поровну. Не забудьте отметить себя объедки. Ведь если вы потеряете хотя бы одну цифру, оригинальный номер должен быть разным.
- 54/2=27, остаток 0.
- 27/2=13, пишем 1 в остальные. Наши номеров из остальных создать двоичный код, который надо читать в обратном порядке.
- 13/2=6. Здесь единица в остатке, мы пишем его.
- 6/2=3 с остатком 0. В окончательные цифры ответа должны быть больше, чем всех действий, совершенных вами.
- 3/2=1 с остатком 1. Записанный баланс и число 1, которое является окончательным разделением.
 Вам будет интересно:Видео звонки и видео конференции колл/контакт-центров.
Вам будет интересно:Видео звонки и видео конференции колл/контакт-центров.
Если вы принять ответ, начиная с цифры в первом акте, в результате 10011011, но это неверно. Двоичные числа должны быть переписаны в обратном порядке. Вот окончательный результат перевода числа: 11011001. Смысл, и подход к измерению информации использовать данные такого формата для хранения и передачи. Двоичный код записывается в таблицу код, и там хранится, пока требуется, чтобы показывать его на экране монитора. Затем передача информации в обычной форме, называется декодированием.
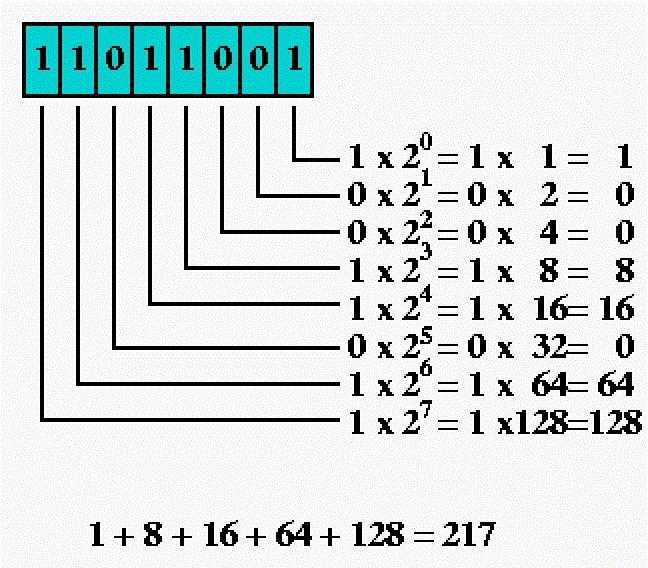
На картинке вы можете наглядно увидеть алгоритм перевода из двоичной форме десятичного кода. Она осуществляется по простой формуле. Первая цифра кода умножается на 2 в степени 0, добавить к нему следующую цифру умножают на 2, в большей степени, и так далее. В результате, как вы можете видеть на картинке, мы получим такое же количество, как и оригинал при кодировании.
Алфавитный подход к измерению информации: сущность единицы
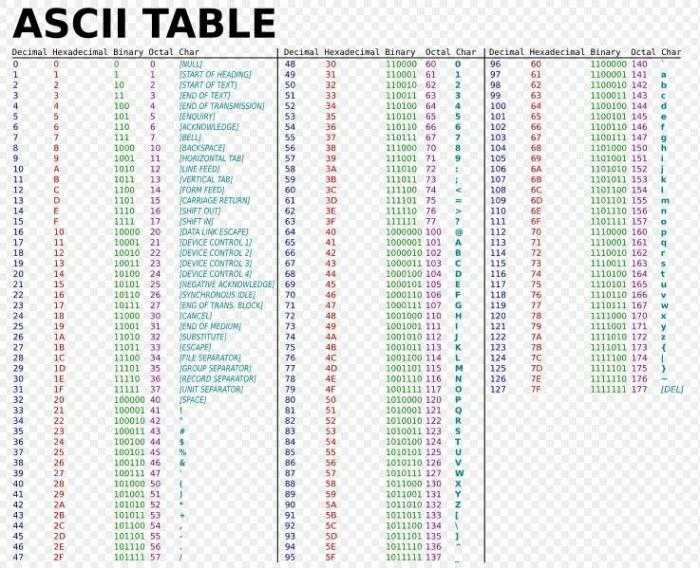
Для измерения объема данных в последовательность текстовых символов, вы должны использовать существующий подход. Не важно содержание текста, главное - пропорции знаков. Из-за этого аспекта, вычисленное значение текстовых сообщений, закодированных на компьютер. В соответствии с количественным подходом значение текста пропорциональна количеству символов, вводимых с клавиатуры. Благодаря такому способу измерения объема информации часто называют объемными. Символы могут быть совершенно разные по величине. Понятно, что цифры 0 и 1-это 1 бит информации, а буквы, знаки препинания, пробел. Вы можете ознакомиться с таблицей ASCII, чтобы узнать двоичный код токена. Для расчета необходимого объема нам текст, нужно добавить вес все признаки – составные части всего текста. Это алфавитный подход к определению количества информации.
В информатике существует много терминов, которые все чаще используются в повседневной жизни. Так, в алфавите в информатике понимается совокупность всех символов, включая скобки, пробел, знаки препинания, символы кириллицы, латиницы, которые ничего, кроме текстовой части. Есть два определения, которые будут рассчитываться эта стоимость.
1. Благодаря первому определению, можно рассчитать частоту встречаемости символов в текстовом сообщении, когда вероятность их возникновения совершенно разные. Итак, мы можем сказать, что некоторые буквы в русских словах появляются очень редко, например, "B" или "Е".
2. Но в некоторых случаях это более целесообразно, чтобы рассчитать необходимое значение, представляя ravnomernoe появление каждого персонажа. И тогда вы будете использовать другую формулу.
Это алфавитный подход к измерению информации.

Появление Ravnomernaya символов в текстовом файле
Чтобы объяснить это определение, надо предположить, что все символы в тексте или сообщения появляются с такой же частотой. Чтобы вычислить, какой объем памяти они занимают в компьютер, вам нужно, чтобы испытать теорию вероятностей и простые логические выводы.
Например, на экране монитора отображаются. Перед нами стоит задача: посчитать, какой объем оперативной памяти он занимает. Пусть текст состоит из 100 символов. Получается, что вероятность одна буква, символ или знак, должны быть одной сотой части от общего объема. Если вы читали книгу по теории вероятности, можно найти достаточно простую формулу, которая точно определяет числовое значение вероятности появления символа в любой позиции текста.
Я полагаю, что доказательство формул и теорем не всем будет интересно, поэтому, с учетом формул знаменитых ученых, система отображает расчетное выражение:
я=lоg2(1/п)=log2N(бит); 2И=Н
где i-это сумма, которую мы должны знать P-это численное значение вероятности появления символа в позиции N, в большинстве случаев, равен 2, потому что компьютер кодирует информацию в двоичный код, состоящий из двух величин.
Алфавитный объемный подход к измерению информации означает, что вес одного символа знака равен 1 бит-минимальная единица измерения. По формуле, можно определить, чему равняется байт, килобайт, мегабайт и т. д.
Различные вероятности появления символов в тексте
Предполагая, что признаки появляются с разной частотой (соответственно, в любой позиции текста и вероятность их наступления), то можно сказать, что их информационные веса тоже разные. Вы должны рассчитать по другой формуле измерения информации. Алфавитный подход и универсальный, который предполагает либо одинаковые, либо различные вероятности частоты появления символа в тексте. Мы не будем затрагивать сложная формула расчета стоимости с учетом различной вероятности появления символа. Вы должны понимать, что такие буквы, как "Г", "Х", "ф", "ч", в русских словах встречаются гораздо реже. Поэтому необходимо рассмотреть частоту встречаемости по формуле. После некоторых вычислений, исследователи пришли к выводу, что информационный вес редко встречающихся символов гораздо больше, чем вес буквы, которые встречаются часто. Чтобы рассчитать объем текста, необходимо учитывать величину повторений каждого символа и его информационный вес и размер алфавита.
Измерение информации: тонкости семантического аспекта
Вам будет интересно:Виды и эффективность рассылок в колл-центрах.
Вы можете игнорировать алфавитный подход к измерению информации. Информатика предлагает и другой аспект данных измерений имеет смысл. Там уже решена немного другая проблема. Например, человек, сидящий за компьютером, получает информацию о явлении или какой-либо предмет. С самого начала ясно, что он ничего не знает, поэтому существует целый ряд возможных или ожидаемых вариантов. После прочтения сообщения, неопределенность исчезает, остается только один параметр, значение которого должно быть рассчитано. Обратившись к вспомогательной формулы. Сумма будет рассчитываться в минимальная единица – бит. Как алфавитный подход к измерению количества информации, правильная формула обусловлена тем, что возможны 2 ситуации: разные и равные вероятности появления событий.
Событий, встретиться с равной вероятностью
Как и в случае, когда применяется к объективной алфавитный подход к измерению информации, нужные формулы при содержательном подходе рассчитывается по уже известным лекалам, которые вел ученый Хартли:
2И=Н
где I-величина события, которое мы должны найти, а n-количество событий, встретиться с частотой ravnovesnoi. Значение i является минимальной единицей расчета – бит. Я могу выразить как логарифм.
Пример расчета событий ravnovesnogo
Например, у нас на тарелке-это 64 вареник, один из которых спрятан сюрприз вместо мяса. Вам нужно рассчитать, сколько информации содержится в случае когда вытащил этот вареник с сюрпризом, то есть проводить измерения информации. Алфавитный подход максимально простым и объективным. В обоих случаях использовалась одна и та же формула для расчета количественного объем информационных материалов. Заменить известную формулу для величины, а именно: 2i=64=26. Результат: я=6 бит.

Измерительной информации с учетом различных вероятностей появления события
Допустим, у нас есть некоторое событие с вероятностью p. Мы предполагаем, что значение i вычисляется в битах, является ряд, характеризующий тот факт, что событие произошло. Исходя из этого, можно утверждать, что значения могут быть рассчитаны по действующей формуле, а именно: 2i=1/п.
Различия между алфавитным и содержательным подходами к информационной размерности
Чем объемный подход отличается от осмысленного? Поскольку формула для расчета количества информации абсолютно одинаковы. Разница в том, что алфавитный аспект может быть использован при работе с текстами, и смысл, позволяет решить любую задачу из теории вероятностей для вычисления количества информации определенного события, с учетом вероятности его возникновения.
Выводы
Алфавитный подход к измерению информации, а также информативным и дает вам возможность знать, какие узлы данные и какой объем занимают текстовые знаки или любую другую информацию. Мы можем перевести любые текстовые и цифровые файлы, сообщения в компьютерный код и обратно, всегда знать, сколько памяти они будут занимать в компьютерной вычислительной машины.